https://towardsdatascience.com/self-attention-in-computer-vision-2782727021f6
Self-Attention In Computer Vision
Using the attention mechanism as the building block in computer vision models
towardsdatascience.com
towards data science의 위 글을 번역한 글입니다!
오역한 부분이나 자연스러운 표현을 위해 의역한 부분이 있을 수 있습니다.
별(*)로 시작하는 문장, 문단은 제가 추가한 해설입니다.
잘못된 내용에 대한 지적은 댓글로 부탁드립니다. :)
Transformer 네트워크가 도입된 이래로, 딥러닝에서의 Attention 메커니즘은 NLP 커뮤니티를 비롯한 기계 번역에서 큰 인기를 누리고 있습니다. 하지만, 컴퓨터 비전에서는 Convolutional neural networks(CNN)이 여전히 표준이고, Self-attention은 기존의 CNN 아키텍처를 보완하거나 대체하는 등 서서히 연구의 중심으로 들어오기 시작한 상황입니다. 이 글에서 저는 visual self-attention의 최근 발전을 보이고 가능한 이점을 강조할 것입니다. 이를 위해 저는 최신 Self-attention 기술을 담은 세 가지의 논문을 이야기할 것입니다.
첫 번째 논문은 제가 가장 편안하게 느끼는 의료 이미지 분석에 관한 논문입니다. 실제 사진과 달리, 의료 사진은 사진끼리 아주 많이 닮아있습니다. 그들은 표준화된 위치에서 유사한 파라미터를 사용하여 얻어집니다. 방사선 전문의들에게 있어 이미지를 해석하는 경험은 특정 병을 찾기 위해 정확히 어디를 봐야 하는지 아는 것에서 비롯됩니다. 따라서 Attention이 다른 연구 분야보다 먼저 의학 이미지 분석에 큰 역할을 했다는 것은 놀라운 일이 아닙니다.
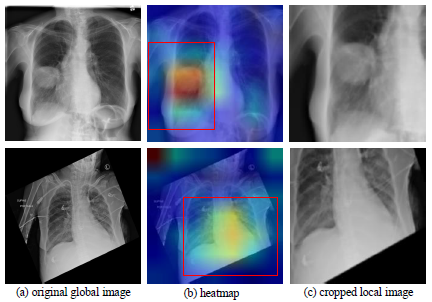
이 논문은 흉부 X선 이미지에서 자동 흉부 질환 분류의 성능을 향상하려고 합니다. 그동안의 네트워크는 흉부 X선 이미지 전체를 보고 병을 감지, 분류하도록 제안되었습니다. 이에 의해 다중 라벨(Multi label) 분류는 손실 함수로 BCE를 사용하거나 혹은 라벨 간 상호 의존도를 포착하기 위해 LSTM을 디코더로 사용한 인코더-디코더 구조를 통해 수행되었습니다. 분류를 위해 X선 이미지 전체를 사용하는 데 따른 문제점은 의료 이미지에서 병변 영역이 전체 이미지에 비해 매우 작을 수 있으며 심지어 경계를 따라 위치할 수도 있어 분류기에 많은 노이즈를 유발하고 검출 정확도를 낮출 수 있다는 것입니다. 더욱이, 흉부 X선 이미지는 종종 정렬이 잘못되기도 합니다. (아래 Figure 1의 두 번째 행) 이러한 정렬 오류는 이미지 주위의 경계를 불규칙하게 해 분류 성능에 부정적인 영향을 미치게 됩니다.
이 논문에서 저자는 검출 정확도를 높이기 위해 이미지의 특정 부분을 크롭하고 전체 이미지와 크롭 된 이미지를 모두 분류하는 Recursive hard attention을 사용하였습니다. (Figure 1의 왼쪽에 위치하는 전체 이미지, 오른쪽의 크롭 된 이미지를 참고하세요.)
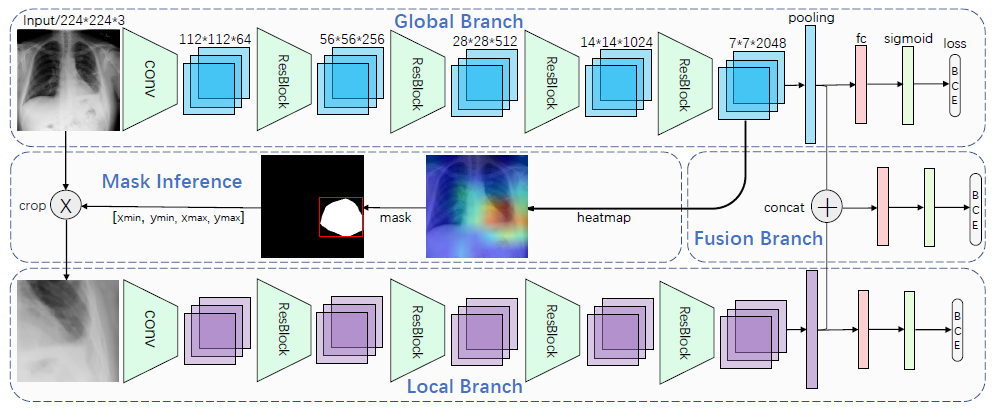
그 네트워크는 세가지 가지로 구성되어 있습니다.
- Global branch는 전체 이미지를 처리하고 크롭 할 부분을 결정합니다.
- Local branch는 Attention 메커니즘과 크롭 된 이미지를 처리합니다.
- Fusion branch는 Global branch와 local branch의 Pooling 아웃풋을 합치고(Concat) Dense layer를 이용해 최종 분류를 실행합니다.
모든 브랜치는 분류 네트워크로 (Figure 2에서 보이는 것과 같이) 끝단에서 병의 존재 유무를 예측하기 위한 다중 클래스 분류를 수행합니다. 분류에 더해, global branch는 크롭 할 영역을 정하기 위한 히트맵을 생성하기 위해 사용됩니다. 히트맵은 특정한 높은 수준의 레이어에서 채널을 따라 가장 큰 값을 세는 방식으로 만들어집니다. 그리고 마스크는 히트맵과 같은 사이즈로 생성이 되게 됩니다. 특정한 포지션 (x, y)에서의 채널별로 최대화된 히트맵의 값이 어떤 임계값보다 크다면, 마스크는 해당 위치에서 1을 할당받게 됩니다. 그렇지 않은 위치에서는 마스크는 0의 값을 갖게 됩니다. 이후, 마스크의 값이 1인 점들의 내부가 크롭 영역으로 결정되게 됩니다. 이미지의 크롭된 영역은 local branch를 거칩니다. 추가적으로 두 브랜치의 아웃풋은 모두 fusion branch에 합쳐져 들어가게 되고 이후 fusion branch는 추가적인 분류를 수행합니다.
네트워크는 세 단계로 학습됩니다.:
1) ImageNet에 의해 pretrain 된 global branch의 Fine-tuning
2) 크롭 이미지를 얻고, local branch의 fine-tuning을 위한 마스크 추론
3) Gobal과 local branch의 아웃풋을 합치고 다른 브랜치의 웨이트를 고정시킨 뒤 fusion branch의 fine-tuning
Fusion branch는 모델의 최종 아웃풋을 만들기 위해 쓰이며 다른 두 브랜치보다 나은 성능을 보일 것으로 기대됩니다.
모델이 attention 관점에서 무엇을 하고 있는지 이해하기 위해서는 우선 Soft와 Hard attention의 차이를 알아야 합니다. 본질적으로 attention은 외부 혹은 내부(self-attention)이 제공하는 웨이트에 따라 네트워크의 특정 feature에 대해 다시 웨이트를 설정합니다. 이때 Soft attention은 이러한 가중치를 연속적인 값이 되게하는 반면, Hard attention은 0 혹은 1과 같은 2진 값을 사용합니다. 이 모델은 이미지의 특정 부분을 크롭 했기 때문에 Hard attention의 예라고 할 수 있습니다. 본래의 이미지에서 크롭 된 부분에는 1을, 나머지 부분에는 0을 설정했다고 볼 수 있기 때문입니다.
Hard attention의 주된 단점은 0과 1 외에는 차별성이 없고 엔드 투 엔드로 학습이 불가능하다는 점입니다. 대신, 저자는 ROI(=* 크롭 할 이미지 영역)를 결정하고 복잡한 절차의 네트워크를 학습시키기 위해 특정 레이어에 활성화 함수를 사용했습니다. Attention gates를 학습하기 위해, 우리는 시그모이드나 소프트맥스와 같은 soft-attention을 이용해야 합니다. 우리는 이제 몇 가지 soft-attention 모델을 살펴볼 것입니다.
Squeeze-And-Excitation-Networks(SENet)
피처맵을 크롭해 웨이트를 재보정하는 Hard attention 대신, 이 논문의 저자는 CNN 특정 레이어에서 채널 별로 값의 가중치를 조정하는 soft self-attention을 사용해 컨볼루션 피쳐들 간 상호 의존성을 모델링하고자 했습니다. 이러한 목적을 위해 저자는 Squeeze-And-Excitation building block을 도입했습니다.
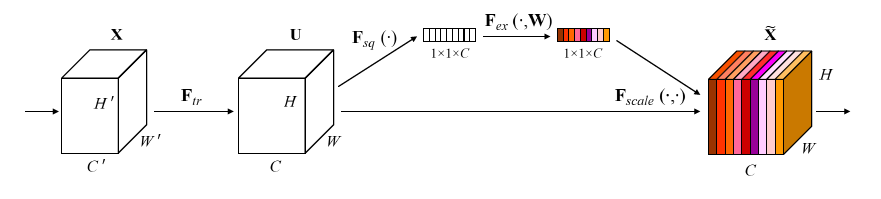
Squeee-And-Excitation block은 다음과 같은 원리로 작동합니다. X를 U로 바꾸는 컨볼루션과 같은 $F_{tr}$ 변환이 있고, 이후 공간(H, W)에 걸친 글로벌한 피쳐를 합계하는 변환 $F_{sq}$을 하게 됩니다. 이것이 바로 squeeze 연산입니다. Squeeze 연산 이후에는 채널별 웨이트를 구성하는 self-gation 작업 $F_{ex}$이 뒤따릅니다. Excitation 연산의 결과인 채널별 웨이트는 $F_{tr}$의 아웃풋에 곱해지게 됩니다. Squeeze 연산의 수식은 다음과 같습니다.

이때 $u_c$는 $F_{tr}$ 연산의 아웃풋입니다. Squeeze 연산은 Global average pooling을 통해 피쳐맵 전체를 임베딩 한 결과를 만들어냅니다. 저자들은 Global average pooling이 전체적인 성능을 조금 증가시키는 점에 주목했지만, Global max pooling 또한 사용될 수 있습니다. 한편 excitation block의 수식은 다음과 같습니다.

따라서 이 excitation은 squeeze block의 아웃풋에 학습된 웨이트 $W_1$을 곱하고, ReLU 함수 δ를 거치고, 또 다른 가중치 $W_2$를를 곱한 뒤, 최종 채널의 결과가 양수임을 보장하기 위한 sigmoid 함수를 거쳐 이루어집니다. 이때, $W_1$은 $r$의 차원을 감소시키는 반면, W2는 그 결과를 다시 원래의 채널 수로 증가시킵니다. 결과적으로 $F_{tr}$의 채널별 피쳐는 excitation block에서 얻은 웨이트와 곱해지게 됩니다. 이 과정은 글로벌한 정보를 이용한 채널에 대한 self-attention 함수로 볼 수 있습니다.
Squeeze-And-Excitation 블록의 핵심 아이디어는 네트워크의 결정 과정에 글로벌한 정보를 포함시켰다는 것입니다. 컨볼루션이 특정한 크기의 지역적인 정보만 보는 반면, Squeeze-And-Excitation 블록은 모든 수용 영역(receptive field)으로부터의 정보를 취합합니다. 저자들의 흥미로운 관찰 결과 중 하나는 excitation 웨이트는 네트워크의 초기 단계에서는 다른 클래스에 대해서도 유사했지만 이후 단계에서 더 구체화된다는 점입니다. 이것은 초반의 레이어는 인풋의 일반적인 특징을 학습하는 반면 이후의 레이어는 점차 차별화된다는 일반적인 가정과 일치합니다. 추가적으로 Squeeze-And-Excitation 블록은 네트워크의 마지막 단계에서는 대부분의 excitation 값이 1이 되며 큰 역할을 하지 못합니다. 이것은 네트워크의 마지막 단계에서는 이미 대부분의 글로벌한 정보가 포함되어 있다는 점으로 설명할 수 있습니다. 또한 Squeeze-And-Excitation 연산이 가져올 새로운 콘텐츠가 더 이상 없다는 것을 의미합니다.
Squeeze-And-Excitation 방식의 가장 큰 이점은 매우 유연하다는 것입니다. 저자는 널리 쓰이는 아키텍처인 ResNet, Inception, ResNeXt 등과의 통합을 언급합니다. 실제로 이 블록은 네트워크의 모든 혹은 일부 단계에 더해질 수 있습니다. 또한 이것은 파라미터의 수 측면에서 약간의 오버헤드만 발생시킵니다. 예를 들어 Squeeze-And-Excitation 블록을 사용하는 SE-ResNet-50의 경우 기존의 2500만 개의 파라미터를 가진 ResNet에서 오직 250만 개의 추가적인 파라미터를 사용합니다. 이는 단지 10% 의 복잡성 증가에 불과합니다.

논문에서 저자는 많은 양의 Squeeze-And-Excitation 블록으로 강화된 학습 아키텍처를 제안했습니다. 특히 그들은 ILSVRC 2017 챌린지에서 Top-5 에러율 2.251%를 기록하며 분류 부문 SOTA를 달성했습니다.
Stand-Alone Self-Attention
마지막으로 보일 논문은 NeurIPS 2019에 제출된 것으로 self-attention을 통해 컨볼루션 레이어를 강화시키는 것뿐만 아니라 Stand-Alone Self-Attention을 사용해 CNN의 self-attention 개념을 한 층 발전시켰습니다. 실제로 저자들은 파라미터의 수를 줄이면서 컨볼루션을 대체할 수 있는 self-attention 레이어를 제안합니다.
컨볼루션 대체에 동기를 부여하기 위해 컨볼루션 연산을 다시 살펴보도록 하겠습니다. 컨볼루션 연산은 3x3과 같은 특정한 사이즈의 웨이트 행렬을 (i, j) 위치의 모든 이웃하는 칸과 곱하고 그 결과를 합산하는 과정으로 구성되어 있습니다. 이것은 다른 공간끼리 웨이트를 공유하는 것을 가능하게 합니다. 또한 파라미터의 수는 입력 크기와 무관합니다.
컨볼루션과 유사하게 논문에서 제안한 self-attention 레이어 또한 주변의 작은 이웃한 영역에 작용하는데, 이를 기억 블록(memory block)이라고 부릅니다. 모든 기억 블록에 대해 single-headed attention은 다음과 같이 계산됩니다.
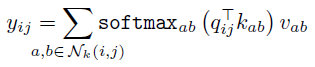
여기서 $q_{ij} = W_qx_{ij}$는 쿼리, $k_{ab}=W_kx_{ab}$는 키, 그리고 $v_{ab}=W_vx_{ab}$는 위치 (i, j)와 이웃 영역의 피쳐로부터 선형 변환으로 계산된 밸류입니다. 행렬 W는 변환을 통해 학습된 값입니다. 공식을 통해 알 수 있듯이, 변환된 픽셀의 중심 $x_{ij}$는 쿼리로 기능하며 키와 함께 이웃 영역의 값과 합산됩니다. 밸류와 곱해질 웨이트를 얻기 위해 이후 소프트맥스 함수가 적용됩니다. 만약 쿼리, 키, 밸류가 무엇인지 모른다면 이 글을 읽어보세요. 저자들은 이 논문에서 단순히 픽셀 피쳐를 깊이에 따라(*= 채널 별, depthwise) 같은 크기의 N 그룹으로 나누는 것을 의미하는 multiheaded attention을 이용했습니다. 이때 attention은 각각의 그룹에 대해 서로 다른 행렬 W를 사용해 계산하고, 결과를 합쳐(concat) 사용합니다. Figure 6은 visual self-attention block을 그림 설명을 제공합니다.
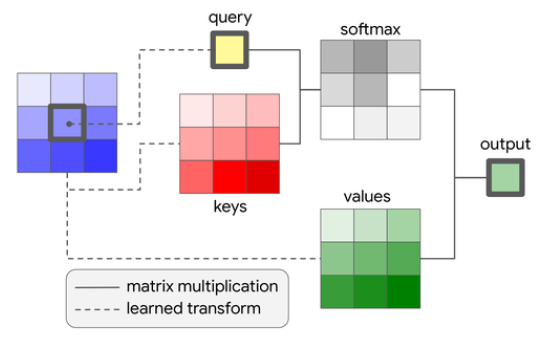
위에서 언급한 접근법을 사용할 때의 한 가지 이슈는 attention block에 위치 정보가 인코딩 되지 않아 공식이 개별 픽셀의 순열, 치환에도 불변한다는 점입니다. 비전 문제에 있어 위치 정보는 매우 중요합니다. 예를 들어 만약 우리가 사람을 탐지하려 한다면, 우리는 입, 코, 귀 등을 어디에서 찾아야 하는지 알아야 합니다. 본래 transformer 논문에서 저자는 위치를 위한 추가적인 인풋으로 사인 (sine) 곡선 형태의 임베딩을 사용했습니다. 하지만 이 논문에서는 비전 태스크에 있어 더 좋은 정확도를 보이는 relative 2D position 임베딩을 사용했습니다. 이 상대적 임베딩은 인접 픽셀 (a, b)와 위치 (i, j)와의 상대적인 거리를 계산한 값으로부터 얻어집니다. 이 거리는 각각 행, 열 거리 $r_{a-i}$, $r_{b-j}$로 나뉩니다. 이 임베딩은 행렬 형태로 합쳐져 쿼리 $q_{ij}$와 다음과 같이 곱해집니다.

이를 통해 소프트맥스 함수에 의해 계산된 웨이트가 거리와 키, 쿼리가 무엇인지에 따라 조정됩니다.
위의 묘사에서 볼 수 있듯이, visual self-attentio은 local attention의 형태를 띱니다. Attention layer는 전체 피처 맵 대신 메모리 블록에 오직 집중합니다. 이 방식의 장점은 파라미터의 수가 매우 감소하고 다른 위치와의 웨이트가 공유된다는 점입니다. 저자는 그들의 self-attention 네트워크가 학습, 사용될 때 CNN보다는 느린 점을 언급했지만, 그 원인으로 고도로 최적화된 컨볼루션 커널이 없는 점, attention layer에 적합하게 최적화된 하드웨어가 없는 점을 꼽았습니다.
저자는 또한 그들의 self-attention block으로 ResNet의 3x3 컨볼루션을 대체한 모델로 ImageNet에서 얻은 결과 몇 가지를 선보였습니다. 그들이 1x1 컨볼루션(픽셀당 계산되는 fully connected layer)과 초반 몇 개의 컨볼루션 레이어를 건드리지 않았다는 점을 주의해주세요. ResNet-26, 38, 50의 모든 구조를 이러한 변화와 함께 실험해본 결과 그들은 12% 적은 FLOPS와 29% 적은 파라미터를 가지고 베이스라인(기본 ResNet)을 능가하는 성능을 냈습니다.
References
[1] Guan, Qingji, et al. “Diagnose like a radiologist: Attention guided convolutional neural network for thorax disease classification.” arXiv preprint arXiv:1801.09927 (2018).
[2] Yao, Li, et al. “Learning to diagnose from scratch by exploiting dependencies among labels.” arXiv preprint arXiv:1710.10501 (2017).
[3] Hu, Jie, Li Shen, and Gang Sun. “Squeeze-and-excitation networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[4] Ramachandran, Prajit, et al. “Stand-Alone Self-Attention in Vision Models.” arXiv preprint arXiv:1906.05909 (2019).
[5] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017.
'공부방 > Vision' 카테고리의 다른 글
| Aliaksandr Siarohin(a.k.a 모션좌) 의 Motion transfer 논문들🐾 (0) | 2021.07.18 |
|---|---|
| COCO Data format과 Pycocotools (4) | 2021.03.30 |
| 도메인과 스타일, 모두 잡았다! StarGAN v2 (0) | 2020.03.23 |
| 진짜 같은 고화질 가짜 이미지 생성하기, StyleGAN (0) | 2020.03.15 |
| GAN과 확률분포(probability distribution) (3) | 2020.03.13 |