들어가기에 앞서...
GAN 이론을 공부하다 보면, '확률분포(probability distribution)' 개념이 계속 등장합니다. 하지만 올해로 통계학과 2학년이나 다름없는 저에게는 선뜻 이해하기 어려운 개념이었습니다.😥 대부분의 글, 발표자료 역시 자세한 설명 없이 넘어가고 있어, 공부 내용을 정리할 겸 글을 작성하게 되었습니다. 제가 공부하고 이해한 선에서 글을 적다 보니, 잘못된 내용이나 표현이 있을 수 있습니다. 그런 부분에 대한 지적은 댓글로 남겨주시면 감사하겠습니다. :)
확률분포
딥러닝 이야기를 꺼내기 전에 확률분포가 무엇인지를 알아보도록 하겠습니다! '확률분포(probability distribution)'는 확률 변수가 특정한 값을 가질 확률을 나타내는 함수를 의미합니다. 가장 쉬운 예로는 주사위를 던지는 상황이 있습니다. 여기서 확률변수 X는 주사위를 던져 나올 수 있는 눈의 수로, 1부터 6까지의 자연수가 되겠군요. 그리고 각각의 확률변수 값이 나올 확률이 존재하는데, 이 경우에는 모두 1/6로 동일합니다. 이를 표와 그래프로 나타내면 아래와 같습니다.
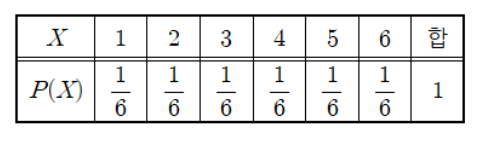
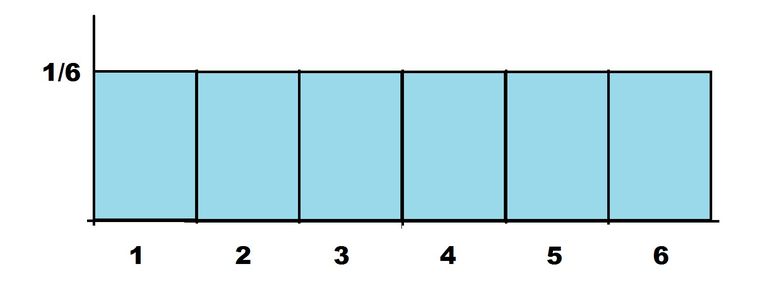
주사위의 눈과 같이 확률변수 X가 이산적으로 나타나는 확률분포를 우리는 이산형 확률분포, 또는 확률질량함수라고 부릅니다. 반대로 키, 몸무게와 같은 데이터는 이산형으로 나타내기가 어렵습니다. 이런 데이터를 나타내는 확률분포를 연속형 확률분포, 또는 '확률 밀도 함수'라고 부릅니다.
정리하자면 확률분포란 임의의 확률변수 X와 그에 해당하는 확률의 대응관계입니다. 이 대응관계는 확률변수 X의 성격에 따라 확률 질량 함수 혹은 밀도 함수라고 부릅니다.
Generator의 기본 메커니즘
GAN에는 기본적으로 Generator와 Discriminator, 2개의 네트워크가 존재합니다. 그 중 확률분포와 관련이 있는 모델은 바로 Generator입니다.
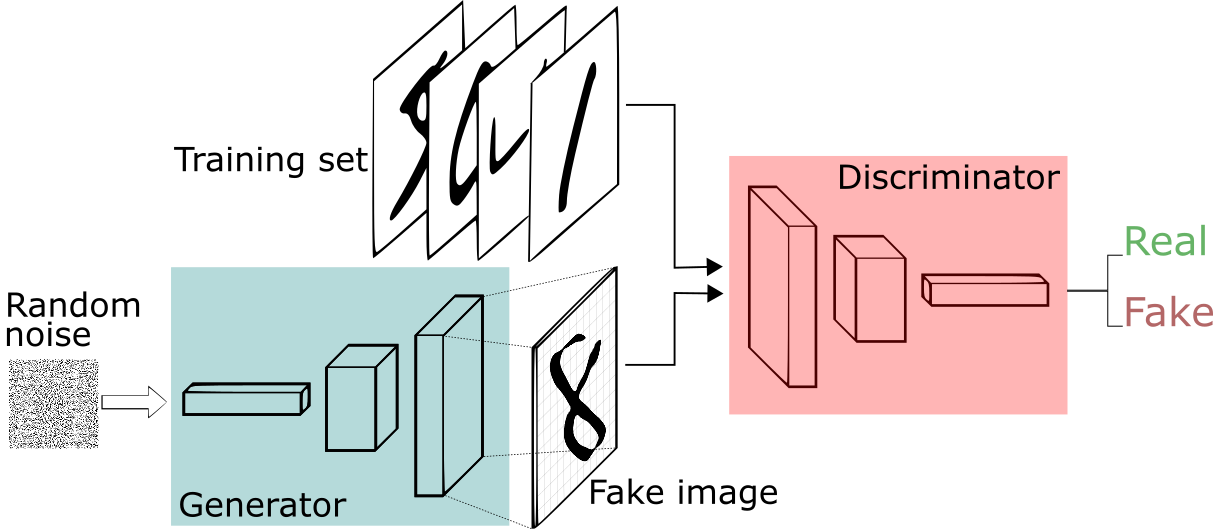
Generator는 어떤 확률분포에서 추출한 랜덤한 벡터를 인풋으로 받습니다. 이미지에 대한 데이터를 압축해 담은(더 낮은 차원으로) 벡터라는 의미에서 잠재(latent) 벡터라고 부릅니다. 그리고 이 벡터는 Generator의 여러 레이어를 거쳐 실제 이미지와 같은 사이즈의 이미지 아웃풋이 됩니다. 구조 자체는 크게 어렵지 않습니다.
Q1. 확률분포에서 벡터를 랜덤하게 추출한다는 게 무슨 말이야?
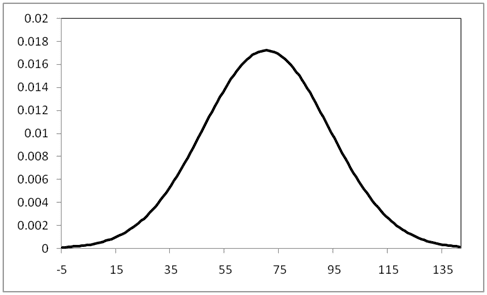
Generator의 인풋이 되는 잠재 벡터를 지금부터는 벡터 z라고 부르도록 하겠습니다. 이 벡터 z는 주로 균등(uniform) 분포나 가우시안 분포에서 추출됩니다. 이 말은 무슨 뜻일까요? (0,1)에서 정의된 균등 분포를 예로 들어봅시다.
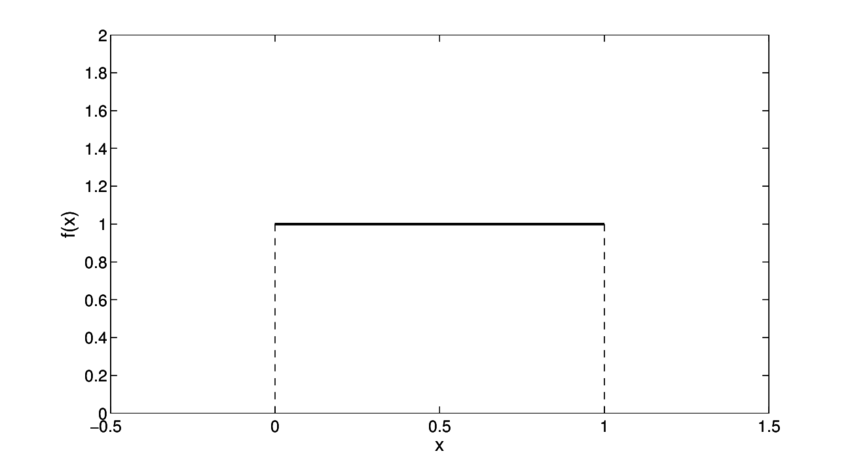
위와 같은 그래프를 나타내는 분포에서 x를 랜덤하게 추출한다는 것은 x는 0과 1 사이의 어떤 값을 갖게 되는데, 그 어떤 값이 뽑힐 확률이 모두 동일함을 의미합니다. 여기서 x만 N차원 벡터 z로 바꾸어 생각하면 됩니다. (물론 그 경우에는 확률밀도함수를 이렇게 2차원 그림으로 나타낼 수 없겠죠?) 어떤 범위 내의, 뽑힐 확률이 모두 동일한 N차원 벡터 중 하나를 뽑아 Generator의 인풋으로 사용하겠다는 것이죠. (뽑힐 확률이 동일한 이유는 uniform 분포이기 때문입니다! 가우시안 분포에서 추출하는 경우에는 벡터마다 뽑힐 확률이 또 달라지겠죠?)
* 저는 (0,1), (0.5,1)과 같은 값을 인풋 벡터로 사용한다는 의미로 착각했었습니다. 부끄럽지만 혹시나 저처럼 오해하시는 분이 있을까 봐 공개합니다. 😅
Q2. 이 그림은 무슨 뜻일까..?
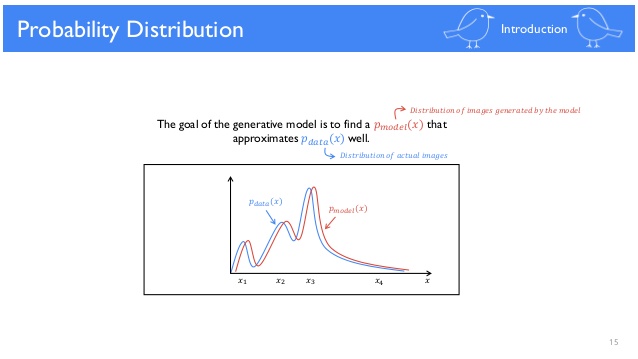
GAN을 공부하다보면 아주 많이 보게 되는 그림입니다. Generator가 학습이 되면서 $P_{model}(x)$이 $P_{data}(x)$로 근사(approximate)된다는 의미인데요, 무슨 뜻일까요? 우선 위 그래프는 확률 밀도 함수로,x는 G(z), 즉 벡터 z가 Generator를 거쳐 나온 이미지를 의미합니다.
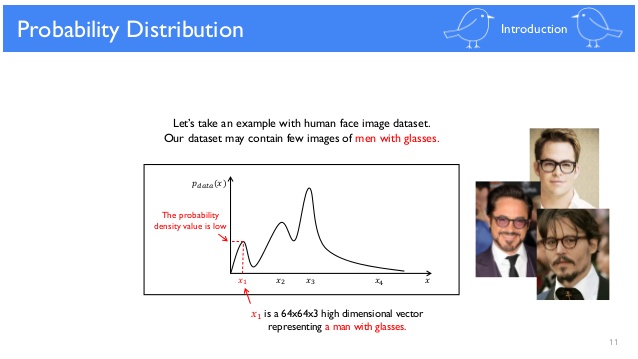
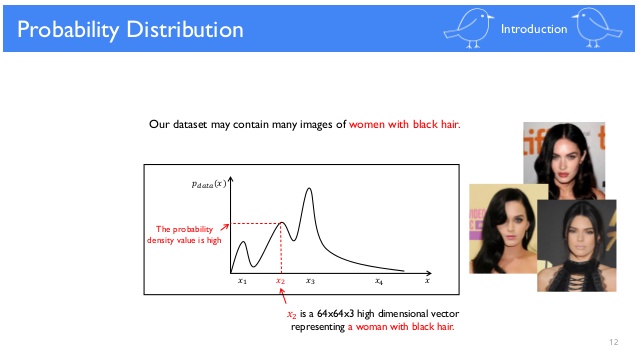

$x_{1}$가 안경 쓴 남성의 이미지라면 $x_{2}$는 좀 더 빈번하게 등장하는 검정 머리의 여성을 나타내고 있다고 생각해볼 수 있습니다. $x_{4}$와 같이 등장빈도가 낮은 이미지는 조금 어색한 사람 이미지네요. $P_{model}(x)$을 $P_{data}(x)$로 근사한다는 것은 Generator를 통해 $x_{4}$와 같은 어색한 이미지보다는 $x_{1}$, $x_{2}$와 같은 이미지를 생성하게 한다는 것을 의미합니다. 벡터 z까지 포함해 학습과정을 살펴보도록 하겠습니다.
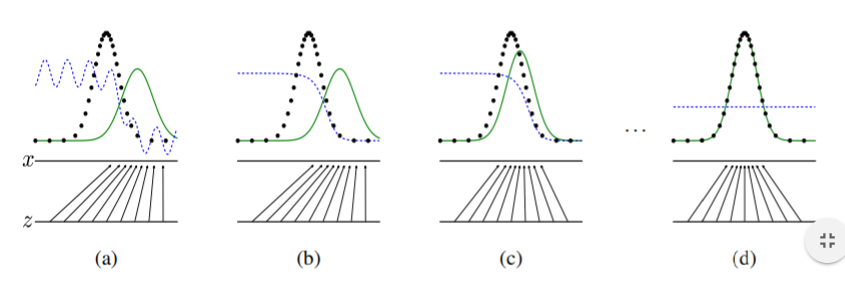
학습이 되지 않은 상태(a)의 generator는 z를 $x_{4}$와 같이 실제 데이터셋에 거의 존재하지 않는 사진으로 만들어냅니다. Discriminator의 피드백을 받으며 점차 generator는 실제 데이터 셋에 존재하는 사진들을 만들어냅니다.
* 벡터 z를 추출하는 분포가 변하는 것이 아닙니다! 이 역시 제가 착각했던 부분...😣
여기까지가 제가 GAN을 공부하면서 헷갈렸던 내용들입니다. 제대로 이해한 게 맞는지 의문이 아직 조금 들지만, 오늘의 저는 이 정도면 만족!😊 계속 공부하면서 더 알게 된 부분, 좀 더 제대로 알게 된 부분 등을 추가 및 수정해나갈 생각입니다.
Reference
https://www.slideshare.net/NaverEngineering/1-gangenerative-adversarial-network
'공부방 > Vision' 카테고리의 다른 글
| Computer vision 분야에서의 Self-Attention (4) | 2020.05.31 |
|---|---|
| 도메인과 스타일, 모두 잡았다! StarGAN v2 (0) | 2020.03.23 |
| 진짜 같은 고화질 가짜 이미지 생성하기, StyleGAN (0) | 2020.03.15 |
| CycleGAN을 만든 사람이 한국인이라고? CycleGAN 논문 뜯어보기 (1) | 2020.03.04 |
| Pytorch(파이토치) DCGAN 튜토리얼, 함께 따라해요! (4) | 2020.02.27 |