https://arxiv.org/abs/1912.01865
StarGAN v2: Diverse Image Synthesis for Multiple Domains
A good image-to-image translation model should learn a mapping between different visual domains while satisfying the following properties: 1) diversity of generated images and 2) scalability over multiple domains. Existing methods address either of the iss
arxiv.org
StarGAN v2 논문을 정리한 글입니다!
오역한 부분이나 자연스러운 표현을 위해 의역한 부분이 있을 수 있습니다.
별(*)로 시작하는 문장, 문단은 제가 추가한 해설입니다.
잘못된 내용에 대한 지적은 댓글로 부탁드립니다. :)
들어가기에 앞서...
팀원들과 프로젝트 회의를 하던 중, 답답한 마음에 GAN KR 페이스북 그룹에 도움을 요청하게 되었습니다. 아무도 댓글을 안 달아주시면 어떡하지 조마조마했는데, 생각했던 것보다 많은 분들이 좋아요도 눌러주시고 댓글도 달아주셨어요. (역시 컴퓨터 하는 사람들은 마음이 따뜻해🥰) 댓글 중 단연 눈에 뜨인 것은 StarGAN! StyleGAN의 한계를 느끼던 참이라 StarGAN을 공부해볼까 망설이던 중이었는데, 곧바로 실천에 옮기게 되었습니다. (StarGAN 논문 저자분까지 직접 등판하신 건 안 비밀) StarGAN v1에 대해 간단히 살펴본 후, 바로 v2 논문을 정리해보도록 하겠습니다!
StarGAN (v1)
https://arxiv.org/abs/1711.09020
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Recent studies have shown remarkable success in image-to-image translation for two domains. However, existing approaches have limited scalability and robustness in handling more than two domains, since different models should be built independently for eve
arxiv.org
StarGAN 논문을 살펴보기에 앞서 논문에서, 그리고 제 글에서 사용하는 단어에 대해 간단하게 정리를 하고 시작하도록 하겠습니다.
- attribute : 이미지의 특징을 의미합니다. 머리 색(hair color), 성별(gender) 등이 될 수 있습니다.
- attribute value : 각각의 attribute가 가질 수 있는 값을 의미합니다. 머리 색(attribute)에 대한 value는 검정. 금발/갈색, 성별에 대한 value는 남성/여성이 되겠죠?
- domain : 같은 attribute value를 가지는 데이터 집합을 의미합니다. 검은색 머리, 금발 머리, 남성, 여성 등이 도메인이 됩니다.
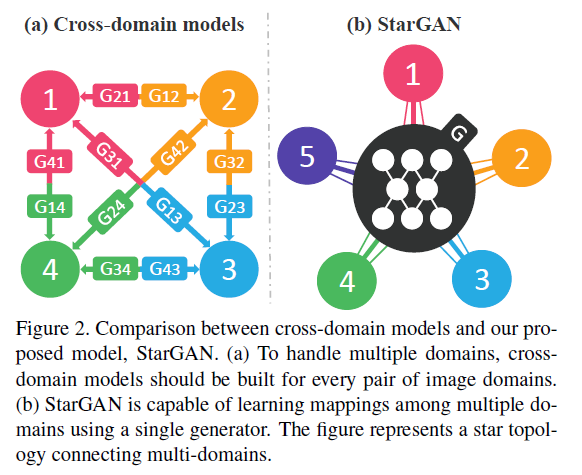
StarGAN은 2018년에 발표된 GAN 모델로, 하나의 모델로 여러 도메인(multi-domain)의 이미지를 생성할 수 있는 모델입니다. 기존의 모델들은 생성하고 싶은 도메인 개수만큼의 모델이 필요했었죠.(a) StarGAN은 한 개의 Generator, 한 개의 Discriminator로 이 어려운 일을 해냅니다!🤩
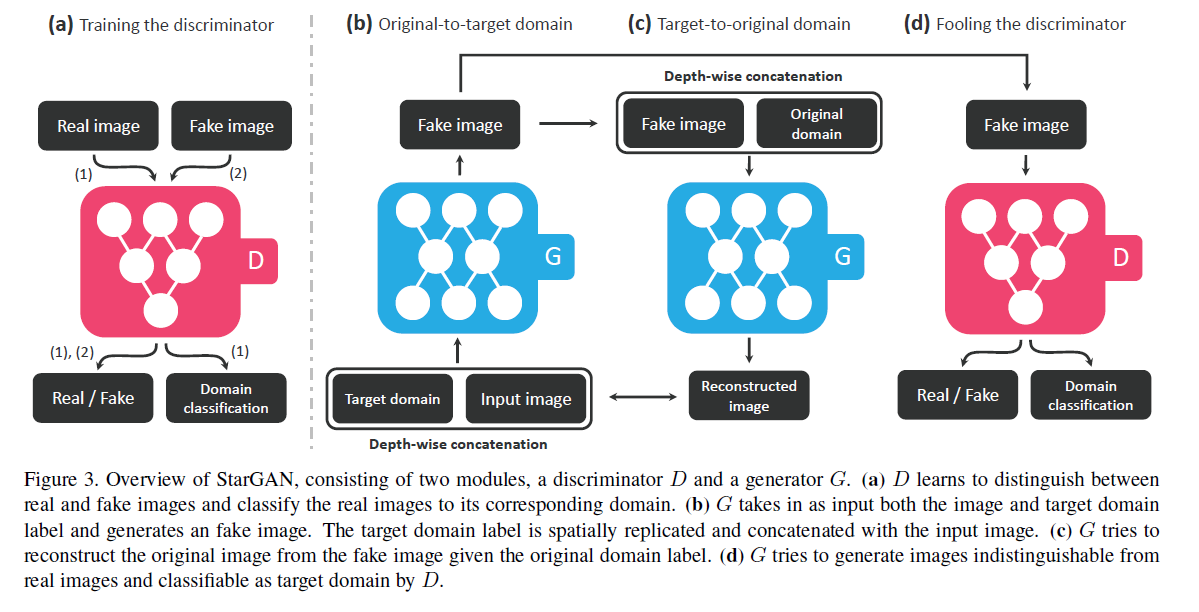
StarGAN (v1)는 여느 GAN과 마찬가지로 Discriminator D와 Generator G 모듈로 구성되어있습니다. 그 구조는 위와 같습니다. 왼쪽(a)부터 하나씩 살펴보도록 하겠습니다.
(a) Training the discriminator
: 가장 먼저 D의 구조입니다. D는 실제 이미지와 가짜 이미지를 구분하는 역할을 합니다. 일반적인 GAN의 D의 역할은 여기까지. 그런데 StarGAN의 D는 'Domain classification'이라는 한 가지 역할을 더 합니다. 인풋 이미지가 어떤 도메인을 가지는지 분류를 하게 하는 것이죠. (ex. 남성 이미지를 남성으로 분류하는지, 금발 이미지를 금발로 분류하는지) 이미지의 도메인 변환이 제대로 되었는지 체크하는 방법입니다.
(b) Original-to-target domain
: G는 이미지와 함께 타깃 도메인을 인풋으로 받습니다. 타깃 도메인은 one-hot vector의 형태입니다. 타깃 도메인을 갖도록 생성된 Fake 이미지는 (c)와 (d)에서 각기 다른 목적으로 사용이 됩니다.
(c) Target-to-original domain
: (b)에서 생성한 Fake 이미지는 원래 이미지의 도메인을 나타내는 벡터와 함께 다시 Generator로 들어갑니다. 이때의 아웃풋을 Reconstructed image라고 부릅니다. Reconstructed image를 원래의 이미지와 비교해 그 차이가 작아지도록 학습됩니다. (Loss function을 통해 조절하는 거죠!)
(d) Fooling the discriminator
: D는 (b)에서 생성한 가짜 이미지를 인풋으로 받아, 진짜 이미지인지 가짜 이미지인지를 구분합니다. (a)에서와 마찬가지로 도메인도 classification을 합니다. 두 결과 모두 G에 피드백되어 G가 더 진짜 같고, 해당 도메인에 적합한 이미지를 만들 수 있게 합니다.
Loss function은 다음과 같습니다.
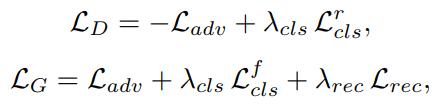
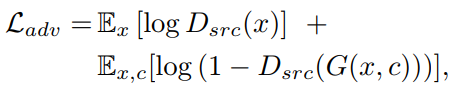
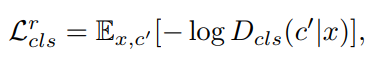
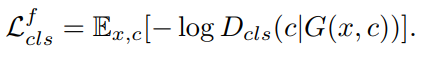
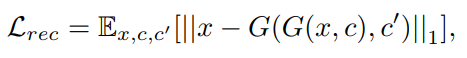
한 모델로 여러 도메인의 이미지를 생성해내는 것 이외에도 StarGAN은 여러 장점을 가집니다. 마스크 벡터를 이용해 특정 도메인에 대해 라벨링이 되지 않은 데이터셋을 처리할 수 있고, (남성 + 금발)과 같이 여러 도메인으로의 변화도 가능케합니다. 하지만 StarGAN v2에 대한 포스팅인 만큼 이 내용들은 언급만 하고 자세히 다루지는 않도록 하겠습니다. 궁금하신 분들은 다른 포스팅이나 Youtube 자료를 활용하시면 좋을 것 같습니다!
Abstract
좋은 image-to-image(I2I) 모델이 가져야 할 특성은 무엇일까요? 이 논문에서는 다음과 같은 두 가지를 꼽고 있습니다.
- 다양한 이미지를 생성할 것 (* = 다양한 스타일의 이미지)
- 다양한 도메인으로의 확장이 가능할 것
이는 곧 StarGAN v2 모델이 두 특성을 가졌다는 뜻으로도 해석할 수 있겠죠? 정답입니다!😊
StarGAN v2은 하나의 모델만으로 두 문제를 모두 해결했고, 기존의 모델들보다도 아주 우수한 성능을 보였습니다.
Introduction
I2I는 두 개의 다른 비주얼 도메인 간의 매핑(*변환)을 학습하는 것이 목표입니다.
이때 '도메인'은 시각적으로 구분되는 이미지의 집합을 의미합니다. 그리고 각각의 이미지는 '스타일'이라고 부르는 독특한 특징을 가지고 있습니다.
이상적인 I2I 변환 방법은 각각의 도메인의 다양한 스타일을 고려해 합성하는 것입니다. 하지만 데이터셋에는 많은 수의 도메인과 스타일이 있기 때문에 그러한 모델을 설계하고 학습시키는 것은 매우 복잡한 일입니다. StarGAN v2는 다양한 도메인을 넘나들며 다양한 이미지를 생성합니다.
StarGAN에서 쓰이던 도메인 라벨은 특정 도메인의 다양한 스타일을 대표할 수 있는 domain-specific style code로 대체되었습니다. 이를 위해 StarGAN v2에서는 mapping network와 style encoder를 도입했습니다. 이전 모델과의 가장 큰 차이점이라고 볼 수 있죠.
StarGAN v2
이제 모델이 어떻게 자세히 생겼는지와 학습에 사용된 목적 함수(objective functions)를 알아보도록 하겠습니다.
Proposed framework
지금부터 $X$와 $Y$를 각각 이미지와 가능한 도메인의 집합이라고 부르겠습니다. $X$에 속하는 이미지 $x$와 $Y$에 속하는 임의의 도메인 $y$가 주어졌을 때 StarGAN v2의 목표는 하나의 generator G만으로 이미지 $x$를 도메인 $y$의 이미지로 변형하되, 다양한 스타일로 변형할 수 있도록 학습하는 것입니다. (* ex. 어떤 남성의 이미지를 여성 도메인으로 바꾸되, 다양한 스타일(어떤 사진에선 진한 화장, 어떤 사진에선 단발)의 여성 이미지로 바꾸어내는 것이죠)
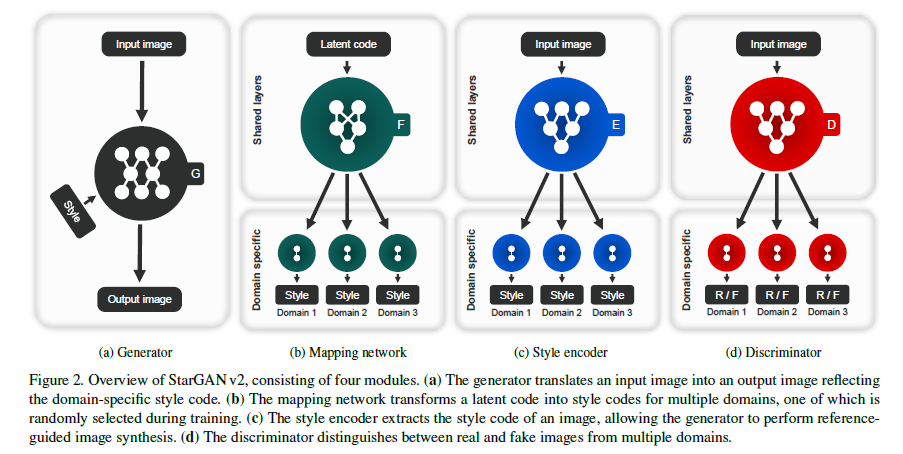
Generator(a)
: Generator G의 역할은 다른 GAN 모델들과 거의 유사합니다. 하지만 이미지($x$)와 함께 스타일 벡터(코드) $s$가 함께 인풋으로 사용됩니다. 이때 $s$는 도메인 $y$의 스타일을 대표하도록 mapping network F나 style encoder E에 의해 만들어집니다. 스타일 $s$는 AdaIN(Adaptive instance normalization)을 통해 주입됩니다.
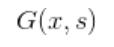
Style encoder(c)
: 주어진 이미지 $x$와 그에 해당하는 도메인 $y$가 주어지면 encoder E는 스타일 벡터 $s$를 추출(extracts)합니다. E는 다른 레퍼런스 이미지에서 다양한 스타일 벡터를 만들어냅니다. 이것은 G로 하여금 레퍼런스 이미지 $x$의 스타일$s$를 반영한 사진을 생성하도록 합니다.
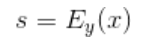
Mapping network(b)
: 잠재 벡터 $z$와 도메인 $y$가 주어질 때 mapping network F는 스타일 벡터 $s$를 만들어냅니다(generate). F는 가능한 모든 도메인에 대해 스타일 벡터를 만들 수 있는, 다중 출력(multiple output branches) MLP(Multiple Layer Perceptron)으로 구성됩니다.
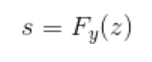
Discriminator(d)
: D는 다중 출력 Discriminator입니다. D의 각 branch는 이미지 x가 해당 도메인의 실제 이미지 같은지 G에 의해 만들어진 가짜 이미지 $G(x,s)$인지 이진 분류할 수 있도록 학습합니다.
Training objectives
$X$에 속하는 이미지 $x$와 이미지 $x$의 오리지널 도메인 $y$(역시 $Y$에 속함)이 주어졌을 때 StarGAN v2 모델을 아래와 같은 목적함수를 사용해 학습시킵니다.
Adversarial objective
: GAN의 핵심, Adversarial loss입니다. 학습과정에서 우리는 잠재 벡터 $z$와 타깃 도메인 $\tilde{y}$를 랜덤하게 샘플링해, 타깃 스타일 벡터 $\tilde{s} = F_{\tilde{y}}(z)$를 생성합니다.
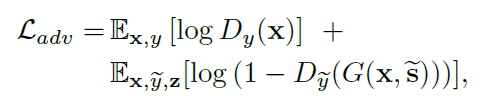
이 목적 함수를 통해 G는 adversarial loss를 통해 이미지 $x$와 $\tilde{x}$를 인풋으로, 아웃풋 이미지 $G(x,\tilde{s})$를 생성하는 법을 학습합니다. Mapping network F는 타깃 도메인 $\tilde{y}$에 맞는 $\tilde{s}$를 만들 수 있도록 학습됩니다.
Style reconstruction
: G가 이미지를 생성할 때 $\tilde{s}$를 이용하도록 강제하기 위해 style reconstruction loss를 이용합니다.
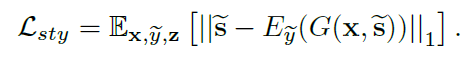
테스트 단계에서, E는 G가 레퍼런스 이미지의 스타일을 반영해 인풋 이미지를 생성하도록 합니다.
Style diversification
: G가 다양한 스타일의 이미지를 생성할 수 있도록 diversity sensitive loss를 사용합니다.
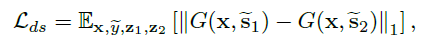
$\tilde{s_1}$과 $\tilde{s_2}$는 각각 랜덤 잠재 벡터 $z_1$와 $z_2$로부터 F가 만들어낸 스타일 벡터입니다. ($\tilde{s_i} = F_{\tilde{y}}(z_i)$) 이 식을 최대화함으로써 G가 다양한 이미지를 생성하기 위한 의미 있는 다양한 스타일 벡터를 찾을 수 있도록 합니다. 이 목적함수는 최적화 지점이 없기 때문에, 선형적으로 웨이트를 0으로 줄여가며(decay) 학습했습니다.
Preserving source characteristics
: 위의 세 식은 G가 생성한 이미지($G(x,\tilde{s})$)가 인풋 이미지 x의 도메인과 무관한 특성을 보존할 것을 보장하지 않습니다. 우리는 이 문제를 cycle consistency loss를 도입해 해결했습니다. CycleGAN에서 등장했던 개념이네요!
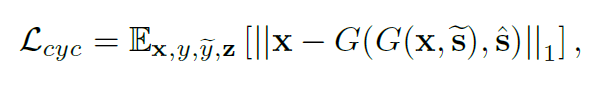
이때, $\hat{s}$는 $E_y(x)$로 인풋 이미지 x에서 추출한 스타일이고 $y$는 이미지 $x$의 오리지널 도메인입니다. 기호가 많이 등장했기 때문에 한 번 정리하고 넘어가도록 하겠습니다!
- $x$ : 오리지널 이미지
- $y$ : 이미지 x의 본래 도메인
- $\tilde{y}$ : 타깃 도메인 (우리는 이미지 $x$를 타깃 도메인의 이미지로 바꾸려고 한다!)
- $\tilde{s}$ : $F_{\tilde{y}}(z)$, 타깃 도메인에 대한 스타일 벡터 (잠재 벡터 $z$를 F를 통해 변형)
- $\hat{s}$ : $E_{y}(x)$, 이미지 $x$에서 도메인 $y$에 대해 추출한 스타일 벡터
따라서 위 식은 타깃 도메인으로 바꾼 이미지를 다시 원래 도메인으로 돌려, 가장 처음의 인풋 이미지 $x$와 유사해지도록 강제하는 식입니다.
Full objective
: D, F, G, E에 해당하는 전체 손실 함수 식은 아래와 같습니다.
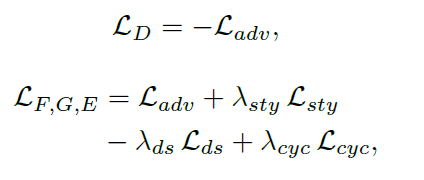
이때 $\lambda$는 하이퍼파라미터로 adversarial loss를 기준으로 각 loss의 중요도를 반영해 정해집니다. StarGAN v2 팀이 $\lambda$를 비롯한 각종 하이퍼파라미터를 어떻게 설정했는지는 논문의 Appendix B에서 확인할 수 있습니다.
Experiments
논문에서는 MUNIT을 비롯한 몇 개의 모델들을 CelebA와 AFHQ라는 동물 데이터셋으로 학습한 뒤, StarGAN v2와 성능을 비교하고 있습니다. 하지만 이 글의 주목적은 StarGAN v2의 구조를 파악하는 것이기 때문에 성능을 비교하는 부분과 StarGAN v2가 나오기까지의 변천사(?)에 대해서는 정리를 생략하도록 하겠습니다. 대신 StarGAN v2가 이미지를 얼마나 잘 만들어내는지 확인해보죠!🧐

위의 사진들은 소스 이미지의 포즈와 identity(인종과 같은 굵직한 특징)를, 레퍼런스 이미지의 헤어 스타일, 메이크업, 수염, 나이 특징을 조합해 만든 이미지들입니다. 머리스타일, 화장 등 스타일이 얼굴 특징과 각도에 맞게 자연스럽게 잘 들어간 것을 확인할 수 있습니다.
Discussion
저자들이 직접 분석한 StarGAN v2의 성공요인은 다음과 같습니다.
첫째, StarGAN v2 모델의 style space는 가우시안 분포의 비선형 변환에 의해 생성됩니다. (StyleGAN에서 쓰였던 아이디어죠!) 이것은 고정된 분포를 사용하는 것에 비해 모델에 유연성을 줍니다.
둘째, StarGAN v2의 스타일 벡터는 multi-branch 인코더와 mapping network에 의해 도메인 별로 만들어집니다.
마지막으로 (논문에서는 Last but not least라고 표현했네요😘) StarGAN v2 모델은 여러 도메인의 데이터를 완벽하게 활용합니다. 각 모듈은 설계에 의해 도메인과 무관한(domain-invariant) 특징들을 학습해 더 낫게 일반화합니다.
(* StarGAN v1에서도 언급되는 내용인데요, 기존의 1:1 모델 같은 경우에는 자신들의 도메인에 해당하는 데이터가 아니면 사용할 수 없게 됩니다. 흑발 도메인에서 금발 도메인으로 변형하는 모델은, 갈색 머리의 사람 이미지를 전혀 활용하지 못합니다. 포즈, 얼굴 형태와 같은 도메인과 무관한 특징들은 자연스러운 사람 이미지를 생성하는 데에 도움이 됨에도 말이죠.)
이 결과, StarGAN v2는 레퍼런스 이미지에서 스타일을 잘 포착하고, 이러한 스타일을 소스 이미지와 잘 결합해냅니다.

Conclusion
이 논문은 I2I translation의 주요 두 가지 과제를 다룹니다. Abstract에서 언급했던 것과 같이, 다양한 도메인을 가진 다양한 이미지를 생성하는 것이죠. StarGAN v2는 이 두 문제 모두를 한 가지 프레임워크로 처리합니다. 그리고 실험 결과들은 이 모델이 다양한 도메인에 걸쳐 풍부한 스타일의 사진을 만들어낼 수 있음을 보여줍니다.
* 이렇게 지금까지 네이버 Clova AI Research에서 발표한 StarGAN v2 논문을 살펴보았습니다. 도메인과 스타일을 한 번에 잡은 엄청난 모델이었습니다. 한국인들이 만들었다니 왠지 뿌듯한 기분-😋 뜬구름 잡는 이야기 같지만 왠지 논문도 쉽게 잘 읽히더라고요. 논문을 같이 읽은 다른 팀원도 같은 이야기를 하는 걸 보니, 12년 한국 정규교육의 비밀인지도 모르겠습니다. 이 논문은 2019년 12월에 발표된 따끈따끈한 논문으로, 아직 공식 코드가 공개되지 않은 상태입니다. (4월에 파이토치 코드가 공개될 예정이라고 합니다!) 오피셜은 아니지만 TensorFlow로 구현한 코드가 있더라고요, 그 코드는 이 곳에서 확인하실 수 있습니다. 위 글에서 잘못된 내용에 대한 지적은 언제나 환영입니다. : )
'공부방 > Vision' 카테고리의 다른 글
| COCO Data format과 Pycocotools (4) | 2021.03.30 |
|---|---|
| Computer vision 분야에서의 Self-Attention (4) | 2020.05.31 |
| 진짜 같은 고화질 가짜 이미지 생성하기, StyleGAN (0) | 2020.03.15 |
| GAN과 확률분포(probability distribution) (3) | 2020.03.13 |
| CycleGAN을 만든 사람이 한국인이라고? CycleGAN 논문 뜯어보기 (1) | 2020.03.04 |