https://arxiv.org/abs/1703.10593
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pairs. However, for many tasks, paired training data will not be a
arxiv.org
Cycle GAN 논문을 정리 및 일부 번역한 글입니다!
오역한 부분이나 자연스러운 표현을 위해 의역한 부분이 있을 수 있습니다.
잘못된 내용에 대한 지적은 댓글로 부탁드립니다. :)
들어가기에 앞서...
동아리 프로젝트를 위해서 요즘 GAN을 공부 중입니다. 지난 주말부터는 GAN알못이었던 저도 어디선가 들어봤던 CycleGAN 공부를 시작했습니다. 자료를 찾던 중, 논문 저자 중 한 분이신 박태성 님께서 직접 진행하신 CycleGAN 강의를 발견했습니다.
처음엔 저자이신지 몰라 뵙고 '왜 자꾸 논문을 직접 쓰신 분처럼 이야기하지?!' 생각하다, 검색을 통해 저자이신 걸 알고 깜짝! 놀랐습니다. 멋져요👏 그리고 연구 퀄리티와 강연에 또 한 번 깜짝! 공부하다 오랜만에 감동(?) 받아서 논문 직접 읽기를 결심하게 되었습니다. 사족은 여기까지 하고, 지금부터 논문을 본격적으로 뜯어보도록 하겠습니다.
* 기존 연구, 관련 다른 모델에 대한 내용은 많이 생략을 하고, CycleGAN에 초점을 맞추어서 정리했습니다. (번역이 아니라 정리입니다!) 등장하는 수식도 적고 논문이 크게 어렵지 않아서 자세히 알아보고 싶으신 분들은 직접 논문을 읽어보시는 것을 추천합니다! 🤗 딥러닝 기초, Vanilla GAN에서 다루는 GAN의 기본적인 개념 역시 자세히 다루지 않았습니다. '나는 GAN에 대해 아무것도 모른다!' 하시는 분은 입문강의로 네이버 D2의 또 다른 강의인 https://youtu.be/odpjk7_tGY0를 추천드립니다.
Abstract
Image-to-image translation은 짝진 형태의 이미지 train 세트를 이용해 인풋 이미지와 아웃풋 이미지를 매핑하는 것이 목표인, 컴퓨터 비전과 그래픽의 한 분야입니다. 하지만 많은 태스크에 있어서 짝이 지어진 학습 데이터를 얻는 것이 불가능합니다. 우리는 짝지어진 예시 없이 X라는 도메인으로부터 얻은 이미지를 타깃 도메인 Y로 바꾸는 방법을 제안합니다.
우리의 목표는 Adversarial loss를 이용해, G(x)로부터의 이미지 데이터의 분포와 Y로부터의 이미지 데이터의 분포가 구분 불가능하도록 $ G : X → Y $를 학습시키는 것입니다. 이러한 매핑(함수)은 제약*이 적기 때문에, 우리는 $ F : Y → X $ 와 같은 역방향 매핑을 함께 진행했고, $ F(G(x)) $가 X와 유사해지도록 강제하는 cycle consistency loss를 도입했습니다.
* 제약이 적은 것이 왜 문제가 되는지는 뒷부분에서 자세히 알아봅시다.
짝진 학습 데이터가 없었음에도 불구하고 collection style transfer, object transfiguration, season transfer, photo enhancement와 같은 태스크에서 퀄리티 높은 결과가 나타났습니다.

Introduction
이 논문에서는 짝지어진 학습 예시 없이 같은 것을 할 수 있게 학습하는 방법 (: 이미지의 모음에서 특징을 파악한 후 다른 이미지 모음에 어떻게 이 특징을 적용(translate)할지를 제시합니다. 우리는 도메인들 간(같은 모음의 이미지, ex. 모네의 그림들, 말 그림들..)에는 몇몇의 근본적인 관계가 존재한다고 가정했습니다. 우리는 $\widehat{y}$과 $y$를 구분하도록, 즉 적대적(adversary)으로 학습된 모델을 이용해 이미지$y\in Y$과 구분되지 않는 아웃풋 $\widehat{y} = G(x), x\in X$을 산출하는 $ G : X → Y $를 학습시킵니다. *
* Vanilla GAN의 가장 기본이 되는 개념입니다.
하지만 이런 식의 translation이 개개의 인풋 $x$와 $y$가 의미 있는 방식으로 짝지어지는 것을 보장하진 않습니다. 실제로 단독의 Adversarial objective는 학습시키기가 어렵습니다. 위와 같은 보통의 과정은 종종 잘 알려진 문제인 mode-collapse(어떤 인풋 이미지든 모두 같은 아웃풋 이미지로 매핑하면서 최적화에 실패하는 것)*로 이끌곤 합니다.
*Discriminator는 이 사진이 진짜인지 가짜로 생성된 이미지인지만 구분하기 때문에, 인풋과 전혀 상관이 없는 데이터더라도 Discrminator를 통과할 수 있게 됩니다.
이러한 이슈는 우리의 목적 함수에 구조를 추가할 것을 요구합니다. 따라서 우리는 tranlsation이 'cycle consistent(주기적 일관성)'이어야 한다는 속성을 이용합니다. 우리가 영어로 된 문장을 불어로 번역했다면, 그 불어 문장을 영어문장으로 번역했을 때 본래의 영어 문장처럼 될 수 있게요. 우리는 이 구조를 G와 F를 동시에 학습하고 $F(G(x))\approx x $, $F(G(x))\approx x $게하는 cycle consistency loss를 추가함으로써 적용했습니다. Cycle consistency loss와 adversarial losses를 X와 Y에 적용함으로써 우리의 전체 목적함수가 완성됩니다.
Related work
이 파트에서는 GANs(Generative Adversarial Networks)의 기본 개념부터 해결하고자 하는 태스크인 Image-to-Image Translation이란 무엇인지 등 많은 관련 연구를 살펴봅니다. 하지만 이 부분은 다루지 않는 것으로 정했기 때문에 Related work 부분은 넘어가도록 하겠습니다!
Formulation
우리의 목표는 주어진 도메인 X와 Y를 매핑하는 함수를 학습하는 것입니다.
- $x$는 $X$에 속하는, $y$는 $Y$에 속하는 샘플입니다.
- $x\sim p_{data}(x)$, $y\sim p_{data}(y)$입니다.
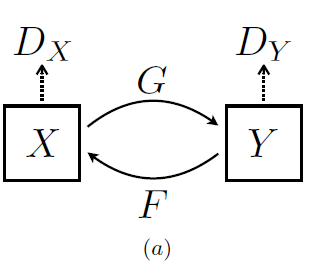
- 위의 그림 (a)와 같이 우리의 모델은 두 개의 매핑 함수 $G : X → Y$와 $F : Y→X$를 포함합니다.
- 추가로 우리는 두 개의 적대적인(adversarial) discriminator $D_{X}$와 $D_{Y}$를 도입합니다.
- 우리의 목적함수(objective)는 adversarial losses와 cycle consistency losses, 두 종류의 항으로 구성되어 있습니다.
Adversarial Loss
우리는 두 매핑 함수 모두에 adversarial losses를 적용했습니다.
함수 $G : X → Y$와 $D_{Y}$에 대해서는 아래와 같은 목적함수를 적용합니다.
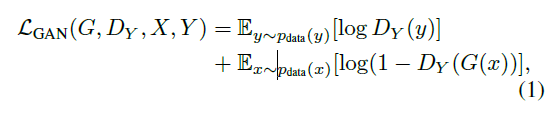
G는 위의 함수를 최소화시키는 것이, 반대로 D는 위의 함수를 최대화시키고자 합니다. $min_{G}min_{D_{y}}L_{GAN}(F,D_{y},Y,X)$으로 나타낼 수 있습니다. 함수 $F : Y→X$와 $D_{y}$ 대해서도 유사한 adversarial loss를 적용합니다. 이는 $min_{F}max{D_{x}}L_{GAN}(F,D_{x},Y,X)$로 나타낼 수 있습니다.
Cycle Consistency Loss
Introduction에서 언급한 것과 같이 mode collapse 문제가 생길 수 있기 때문에, Adversarial losses 단독으로는 매핑 함수를 제대로 된 학습을 보장하기 어렵습니다. 가능한 매핑 함수의 공간을 줄이기 위해, 아래의 그림(b), (c)와 같이 매핑 함수는 cycle-consistent 해야 합니다.
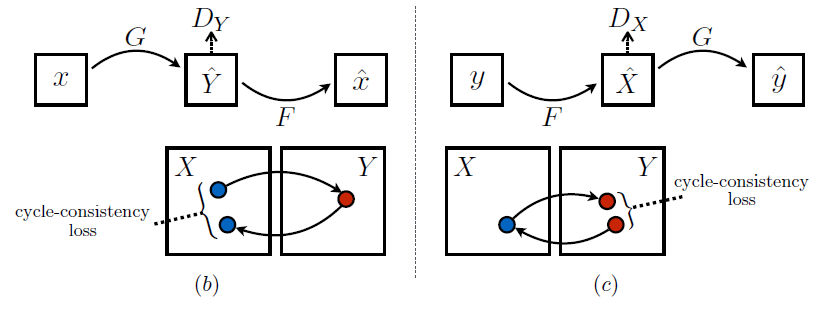
우리는 이러한 행동을 cycle consistency loss를 이용해 유도했습니다. 식은 아래와 같습니다.
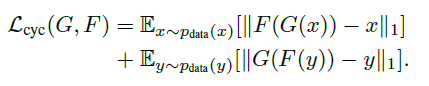
예비 실험에서 우리는 위 식의 L1 norm을 adversarial loss로 대체했었으나 성능 향상을 관찰할 수 없었습니다. Cycle consistency loss가 유도한 결과는 아래 그림에서 볼 수 있습니다.

위 그림에서 재건된 이미지 $F(G(x))$가 인풋 이미지 $x$와 유사한 것을 확인할 수 있습니다. 😊
Full objective
우리의 목적함수 전체는 다음과 같습니다.
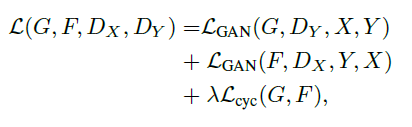
λ는 두 함수(= 위 식에서의 첫 번째 항과 두 번째 항)의 상대적인 중요도에 따라 결정됩니다. 우리가 풀고자 하는 목표는 다음과 같습니다.
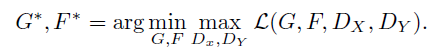
이후 파트에서 우리는 우리의 방법을 adversarial loss만 단독으로 사용할 때, cycle consistency loss만 단독으로 사용할 때와 비교합니다. 그리고 경험적으로 두 목적 함수(adversarial과 cycle consistency loss)를 모두 중요한 역할을 하고 있다는 것이 나타납니다.
Implementation
Network Architecture
우리는 우리의 generative 모델로 neural style transfer와 super-resolution에 좋은 결과를 보인 논문에서 사용된 구조를 채택했습니다. 이 네트워크는
- 두 개의 stride-2 convolutions,
- several residual blocks, ( = shortcut, skip connection)
- 두 개의 factionally strided convolutions(stride = 1/2)를 포함합니다.
- 128*128 이미지에는 6 블록, 256*256 혹은 그 이상의 해상도의 이미지에는 9 블록을 사용합니다.
- 또한 instance normalization을 이용합니다.
- Discrminator는 70 * 70의 겹치는 이미지가 진짜인지 혹은 가짜인지 구분하기 위한 70*70 PatchGANs를 사용합니다. Patch 수준의 discriminator 구조는 더 적은 파라미터를 갖고 있고, 임의의 사이즈의 이미지에 모두 적용 가능합니다.
Training details
우리는 모델 학습 과정을 안정화시키기 위해 두 가지 기술을 적용했습니다.
첫 번째는 $L_{GAN}$의 negative log likelihood 함수를 least-squares loss로 대체했다는 것입니다. 이 loss가 학습 과정에서 더 안정적이었고 더 좋은 품질의 결과를 낳았습니다. 실제로 GAN Loss $L_{GAN}(G,D,X,Y)$에 대해, $G$는 $E_{x\sim p_{data}(x)}[D(G(x)-1)^2]$를, $D$는 $E_{x\sim p_{data}(y)}[(D(y)-1)^2] + E_{x\sim p_{data}(x)}[D(G(x))^2]$를 최소화하는 방향으로 학습합니다.
두 번째는, 모델의 진동(oscillation)을 줄이기 위해 discriminator를 최신의 generator가 생성한 하나의 이미지를 이용하기보다는 지금까지 생성된 이미지들을 사용했다는 것입니다. 우리는 이전에 생성된 이미지 50개를 저장할 수 있는 버퍼를 이용했습니다.
모든 실험에 있어
- λ는 10으로 두었습니다.
- 배치 사이즈는 1이었고, Adam solver를 이용했습니다.
- 처음 100 epoch에 대해서는 learning rate 0.0002를 유지하였고, 이후 100 epoch에서는 선형적으로 0에 가까워지게 lr를 줄여가며 학습했습니다.
Results
Evaluation
pix2pix와 같은 데이터 셋과 평가지표(metrics)를 사용해서, 우리의 방법을 몇 가지 baseline과 양적, 질적 두 기준 모두로 비교했습니다. 도시 풍경 데이터셋에서의 semantic label ↔ photo 태스크, Google map으로부터의 aerial photo(공중사진) ↔ 지도 태스크를 포함합니다. 또한 loss function에 대한 연구도 진행했습니다.
Evalution metrics
- AMT perceptual studies
: 사람을 대상으로 한 실험입니다. 참가자들에게는 실제 사진 혹은 지도와 (우리의 알고리즘 혹은 baseline 모델을 통해 생성된) 가짜 이미지를 보여준 후 그들이 진짜라고 생각하는 것을 선택하게 했습니다. 처음 10개에 대해서는 선택이 옳았는지 틀렸는지 피드백을 주었고, 이후 40개를 이용해 알고리즘이 참가자를 속였는지를 테스트했습니다. - FCN score
: perceptual studies가 얼마나 그래픽이 실제 같은지를 테스트하는 데에 있어서는 매우 좋은 기준이었음에도, 우리는 또한 사람을 대상으로 한 실험이 필요하지 않은 automatic 한 양적 기준을 찾고 싶었습니다. 이를 위해 우리는 'FCN score'를 채택했습니다. - Semantic segmentation metrics
: 사진을 라벨링 하는 성능을 평가하기 위해 우리는 per-pixel 정확도(accuracy)와 IOU를 포함하는 기본적인 평가지표를 이용했습니다.
Baselines
논문에서는 CoGAN, SimGAN, pix2pix와 같은 다양한 다른 모델과 CycleGAN에게 같은 태스크를 시킨 후, 결과를 비교합니다. Baselines 파트에서는 이런 다른 모델들에 대해 간단히 설명하고 있습니다. 하지만 이 글의 주목적은 CycleGAN에 대해 알아보는 것이기 때문에 이 부분은 넘어가도록 하겠습니다.
Comparison against baselines
여러 다른 모델과 Evaluation metrics에서 알아본 평가 지표를 기준으로 CycleGAN의 성능을 한껏 뽐내는 부분입니다.
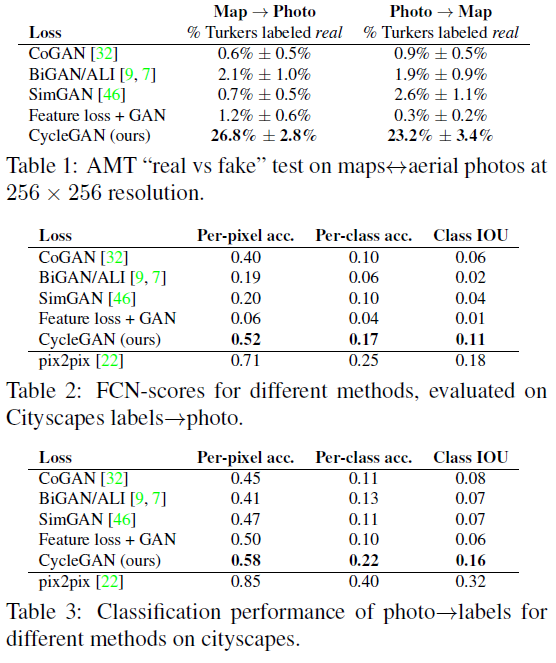
당당하게 Ours라고 적힌 CycleGAN이 대체로 우수한 성능을 보이고 있는 것을 확인할 수 있습니다. 2번째, 3번째 표에서는 pix2pix가 조금 더 우수한 성능을 내고 있네요.
Analysis of the loss function
Full objective에서 이야기했던 이후 파트가 바로 여깁니다! 연구팀은 Loss function을 다양하게 바꾸어가며 (ablation study) 실험을 진행합니다.
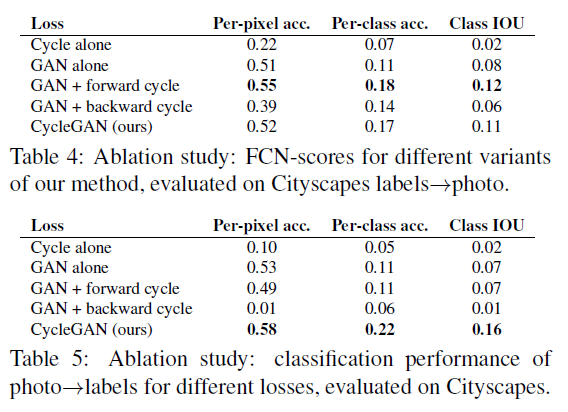
논문에서 최종적으로 채택한 방법인, adversarial loss와 cycle loss를 모두 사용할 때가 성능이 가장 좋았습니다. (사실 그러니까 채택을 했겠죠?)

Image reconstruction quality

맨 오른쪽이 CycleGAN을 통해 재생성한 이미지인데요, 원본과 꽤나 비슷한 것을 확인할 수 있었습니다. 바꾼 이미지를 다시 원본과 유사하게 돌릴 수 있게 학습한다는 아이디어가 정말 대단한 것 같아요😋
Application
논문에서는 짝진 학습 데이터가 없는 태스크에 대해 모델을 적용한 결과를 여러 가지 보여주는데요, 백문이 불여일견! 직접 그 결과를 눈으로 확인해보도록 하겠습니다.

그런데 여기서 $L_{identity}$라는 개념이 등장합니다. 연구진은 그림으로부터 사진을 생성하는 태스크를 실행하는 중, generator가 종종 낮의 그림을 해 질 녘의 사진으로 바꾸는 것과 같은 문제가 있었다고 합니다. 따라서 인풋과 아웃풋의 색 구성을 보존하기 위해 추가적인 loss인 $L_{identity}$를 도입하게 됩니다. 이 loss는 타깃 도메인의 실제 샘플, 그러니까 그림이 아닌 사진이 인풋으로 들어왔을 때는 사진 자기 자신을 아웃풋으로 산출하도록 generator를 regularize 합니다. 그 식은 아래와 같습니다. 그럼 마저 다른 적용 사례도 살펴볼까요?
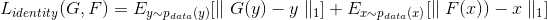


Limitations and Discussion
많은 경우에서 CycleGAN 방식이 좋은 성능을 보였지만, 모든 태스크에서 결과가 긍정적이었던 것은 아니었습니다. 아래 그림에서 몇 가지 실패사례를 확인할 수 있는데요,

연구팀은 여러 가지 유형으로 실패 원인을 분류했습니다. 총 3가지 정도가 있었는데요, 직관적으로 이해할 수 있었던 이유 한 가지를 소개하려고 합니다. 말을 얼룩말로 변환하는 모델이 바로 그 예입니다. 말 이미지 트레이닝 셋에는 사람이 타있는 사진이 많은 반면, 얼룩말 이미지 셋에는 사람이 타 있는 사진이 거의 없습니다. (강연에서 말씀하시기를 얼룩말을 사람이 탄 사진은 1장뿐이었다고 합니다.) 이미지 셋 분포의 특징에서 차이가 나기 때문에, 사람이 말을 타고 있는 사진에 대해서는 모델이 잘 변환하지 못하는 모습을 보였습니다.
저자들이 공개한 관련 파이토치 코드는 이 곳에서 확인하실 수 있습니다.
* 자, 이렇게 지금까지 CycleGAN 논문을 함께 살펴보았습니다. 저는 혼자서 논문을 처음부터 끝까지 읽어본 것은 처음이었는데요, 눈을 사로잡는 결과와 문제점을 해결하는 아이디어들이 아무래도 저에게는 새로워서 논문 읽기가 재미있지 않았나 싶습니다. 발생한 문제들에 대해서 직관적으로 이해할 수 있게 예를 들어준 부분도 개인적으로 좋았고요! 앞으로는 이번 논문에서 재미있었던 태스크들을 조금 더 탐구해보려고 합니다.😙
'공부방 > Vision' 카테고리의 다른 글
| Computer vision 분야에서의 Self-Attention (4) | 2020.05.31 |
|---|---|
| 도메인과 스타일, 모두 잡았다! StarGAN v2 (0) | 2020.03.23 |
| 진짜 같은 고화질 가짜 이미지 생성하기, StyleGAN (0) | 2020.03.15 |
| GAN과 확률분포(probability distribution) (3) | 2020.03.13 |
| Pytorch(파이토치) DCGAN 튜토리얼, 함께 따라해요! (4) | 2020.02.27 |