Business Problem Context
주가 데이터 분석을 통해 투자를 해야 할지? / 관련된 risk로는 어떤 것이 있는지? / 어떤 투자가 더 좋을지? / 수익을 얼마나 낼 수 있을지? 등의 질문에 대답할 수 있음
Stock trade data
# Data periodicity
- Tick by tick
- Intraday ; periodic
- Daily / Weekly / Monthly
# Data structure
- Period open / high / low / close
- Period volume

Timeseries data
- 금융 데이터 분석의 기본적인 형태인 Timeseries(시계열) 데이터
- eg. Stock prices / Trading volume / Revenue / Earnings / Losses / Defects
+ 연체는 Default
Corporate actions and market data
- 금융 데이터 분석의 기본적인 형태인 Timeseries(시계열) 데이터
- Market data에 영향을 주는 Corporate Actions
- Dividends (배당금)과 Stock splits / Reverse splits (액면 분할 / 병합)이 있음

# Stock splits
- 하지만 표만 봐서는 Split 여부를 알 수 없음
- eg. 4:1 Stock Split이 될 경우, 이전 가격을 4로 나눠 표기하기 때문에.
# Dividends

- 배당금을 지급할때마다 과거의 Adj Close에서 계속 뺄셈이 일어나기 때문에 과거의 데이터일수록 Diff가 커진다. (라고 이해)
Concepts and Techniques
- Timeseries 데이터에서는 count / mean / std와 같은 통계량이 잘 쓰이지 않음. (이것들은 Population-based data에 유용)
Smoothing with moving averages
- 단순 평균은 데이터의 트렌드를 반영하기 어려움. 따라서 moving averages (이동 평균) 사용
- 하지만 Random noise와 seasonality effects가 방해 요소
- MA를 계산함으로써 단기 / 장기 트렌드를 파악할 수 있음
- MA는 lagging indicator (실제 데이터의 경향을 조금 늦게 반영하는 지표)
# Simple moving average
- 단순 이동 평균
- pandas.DataFrame.rolling()

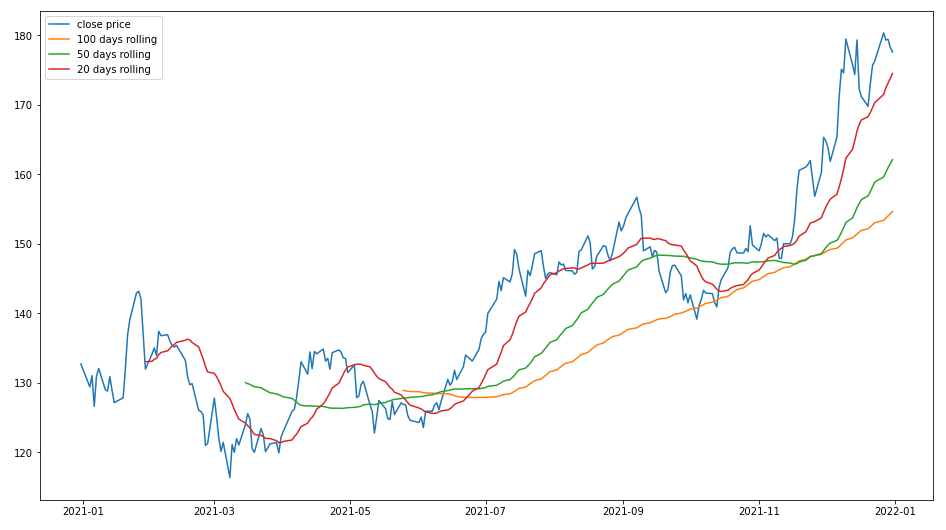
- 이동 평균 시 보는 데이터 일 수가 길어질수록 곡선은 더 smooth 해짐
- 이 외에도 최근 데이터에 가중치를 더 부여하는 Weighted Moving Average (WMA), Exponential Moving Average (EMA)가 있음
Using moving averages in trading strategies
- Noise와 short-term price fluctuations를 필터링한 가격 트렌드를 확인할 수 있음
- 다른 MA 혹은 기본 주가 가격과의 상관관계를 일종의 trigger로 활용할 수 있음
eg. when the price goes above/below the 200-day MA, when the 50-day MA crosses above/below the 200-day MA
Using scaled returns for comparison purposes
- Timeseries 데이터를 scale, normalize할 때 도움이 됨
- 다른 시간 단위의 데이터도 쉽게 비교할 수 있게 도와줌
- 계산 방법 ) 날마다의 percent change에 기반, 시작일을 0으로 두고 Normalize
Calculating a return series
1. Calculate a percent change
- (Current value - Original value) / Original Value
- pandas.DataFrame.pct_change()
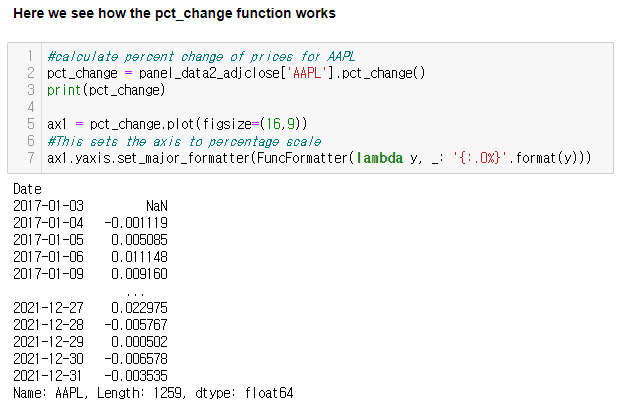
2. Apply cumulatively and normalize
- 시작일의 값을 1로 두고 cumulative return 계산
- Previous value * (1 + Current percent change)
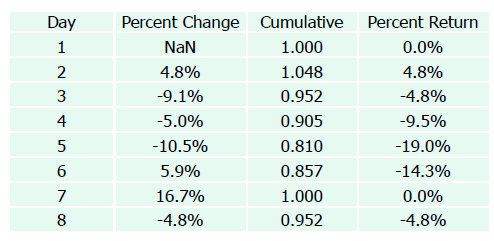
eg. 2행 ; 1 * (1+0.049) / 3행 ; 1.048 * (1 - 0.091)
- pandas.DataFrame.cumprod()
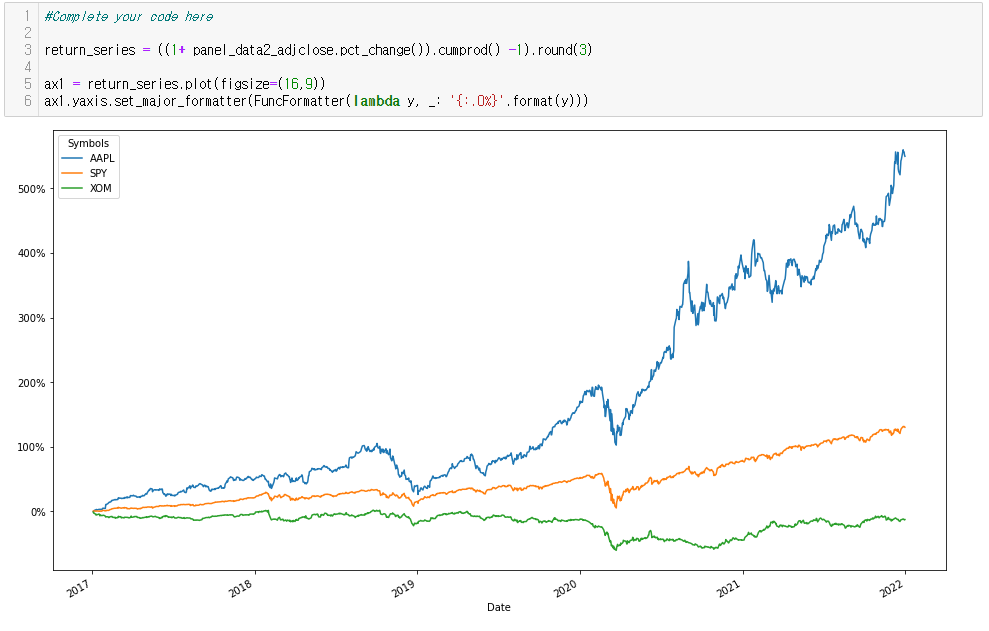
- 최종적으로는 1을 빼서 0%에서 시작해 비교할 수 있도록함
- Return series의 가장 마지막 값은 관찰 기간 동안의 최종 return이 됨
'공부방 > Financial Analysis' 카테고리의 다른 글
| [4] Risk Adjusted Returns (RAR) / Diversification and Portfolio Optimization / Portfolio Analysis (0) | 2022.02.15 |
|---|---|
| [3] Volatility / Distribution of Returns (0) | 2022.02.15 |
| [2] ETF / Annualized Returns / Correlation (5) | 2022.02.14 |